3 Programming theories
In this chapter I discuss the schools of thought that arise from the programming communities themselves. Its purpose is to explain how the different programming traditions perceive programming: what they think programming is, and what kind of things they consider important to focus on when studying programming. These traditions largely make up the existing research on how to carry out programming, and it is these that are taught to would-be programmers at universities. The different schools have a large influence on the way programming is practiced, and it is consequently important to understand these traditions of thought in order to be able to understand programming practice.
The most important schools of thought are computer science, software engineering, and Agile thinking. These are not exclusive schools of thought; for example, computer science has had a considerable influence on both software engineering and Agile thinking. It is not my intention to present a complete description of the fields, and there are many subfields and work carried out by individual researchers that will not be covered by the material here. Rather, my intention is to identify the most important and well-known ideas. For this reason, the scholars cited here are people whose views are respected within their fields. Some have had large influence on their fields, while others are less well known but represent mainstream and uncontroversial ideas.
3.1 Software engineering
3.1.1 The origins of software engineering
Software engineering is, as the name implies, a school of thought within programming that arose from engineering communities and is predominant among those software scholars and professionals who are inclined towards engineering. The first electronic computers constructed in the 1940s during the Second World War were built mainly by electrical engineers. In those early days there was little distinction between the hardware engineers who built the machines, and those who programmed them. While computers slowly gained importance during the 1950s and 1960s, the engineers who had the task of programming them began to see themselves as a distinct group: software engineers.
The first electronic computers were developed for military use. Like other branches of engineering, for example aeronautical engineering, software engineering has since the beginning had strong ties to the military and consequently to the government. The origin of the term “software engineering” is attributed to two conferences sponsored by the NATO Science Committee: one in 1968 on “Software Engineering” and one in 1969 on “Software Engineering Techniques”.1 These conferences did not address the definition of the discipline, or its aim and purpose. The things that were discussed were the various problems and techniques involved in creating software systems, for example in connection with the design, management, staffing, and evaluation of systems, as well as for example quality assurance and portability.2
The connection with military engineering means that many prominent software engineers have worked for the military. The well-known researcher Barry Boehm, for example, worked on the Semi-Automated Ground Environment radar system for the U.S. and Canadian air defence in the beginning of his career in the 1950s.3 Of the 12 represented in George F. Weinwurm’s 1970 anthology On the Management of Computer Programming, at least half have had military careers.
After the war computers soon found uses outside of the military. From the 1950s throughout the 1970s, these uses were primarily within the administration of other branches of government and in “big business”. The big business sector was mostly served by large corporations such as IBM – the well-known software engineer Frederick P. Brooks, Jr., worked for IBM, and also later served the military as a member of the U.S. Defense Science Board.4 The authors in Weinwurm’s anthology without military careers have all had careers with either IBM or other large corporations, such as banks.
1 Naur & Randell 1969. Buxton & Randell 1970.
2 Portability concerns the technical relationship between programs and the machines on which they run. If a program can easily be made to run on several different makes of machines, it is said to be portable.
4 See for example the 1987 Report of the Defense Science Board Task Force on Military Software.
3.1.2 Frederick P. Brooks
In 1964-65 Frederick P. Brooks, Jr., was the manager of the development of the operating system of the IBM 360 computer, a technically innovative machine.1 In 1975 he published the book The Mythical Man-Month: Essays on Software Engineering about his experiences of the project. This book has since become perhaps the most well-known book in the field of software engineering, and has gained a wider reputation.
In Brooks’ approach to software engineering, the main concerns of development are management and organization. The technical part of development is also discussed, but falls outside of the main focus of the book. Brooks’ thinking on management stresses the importance of estimation and the use of formal documents. The undisputed top priority of management is to be on time. Brooks poses the famous question “How does a project get to be a year late?” and gives the laconic answer “ … One day at a time.” 2
In order to avoid slipping schedules, Brooks emphasizes the importance of good estimates of how long programming tasks will take. He also acknowledges that this is very difficult to achieve: nonetheless, managers must do their best, because without good estimates the project will end in catastrophe. Because of the difficulties inherent in estimation, Brooks advocates looking at data for time use in other large projects, to try to discover some general rules of how long programming takes depending on various factors, such as which programming language is used and the amount of interaction between programmers.
Good documentation is important to a successful project, for two reasons. When the manager writes down his decisions he is forced to be clear about the details, and when they are written down they can be communicated to others on the team. Producing a small number of formal documents is critical to the job of the manager. According to Brooks, the purpose of management is to answer five questions about the project: what?, when?, how much?, where?, and who? For each of the questions there is a corresponding document that answers it, and these formal documents form the core basis for all of the manager’s decision making:3
| what? | is answered by | objectives |
| when? | ” | schedule |
| how much? | ” | budget |
| where? | ” | space allocation |
| who? | ” | organization chart |
Besides estimation and documentation, a third important aspect of management is planning. Brooks’ advice to managers is to use the Program Evaluation and Review Technique (PERT) developed by the U.S. Navy in the 1950s, which consists of providing estimates and start dates for all tasks, as well as listing which tasks depend on other tasks. The total duration of the project can then be calculated, as well as the critical tasks, which are those tasks that must not be delayed if the project is to finish on time. Figure 3.1 shows an example of a PERT chart given by Brooks.
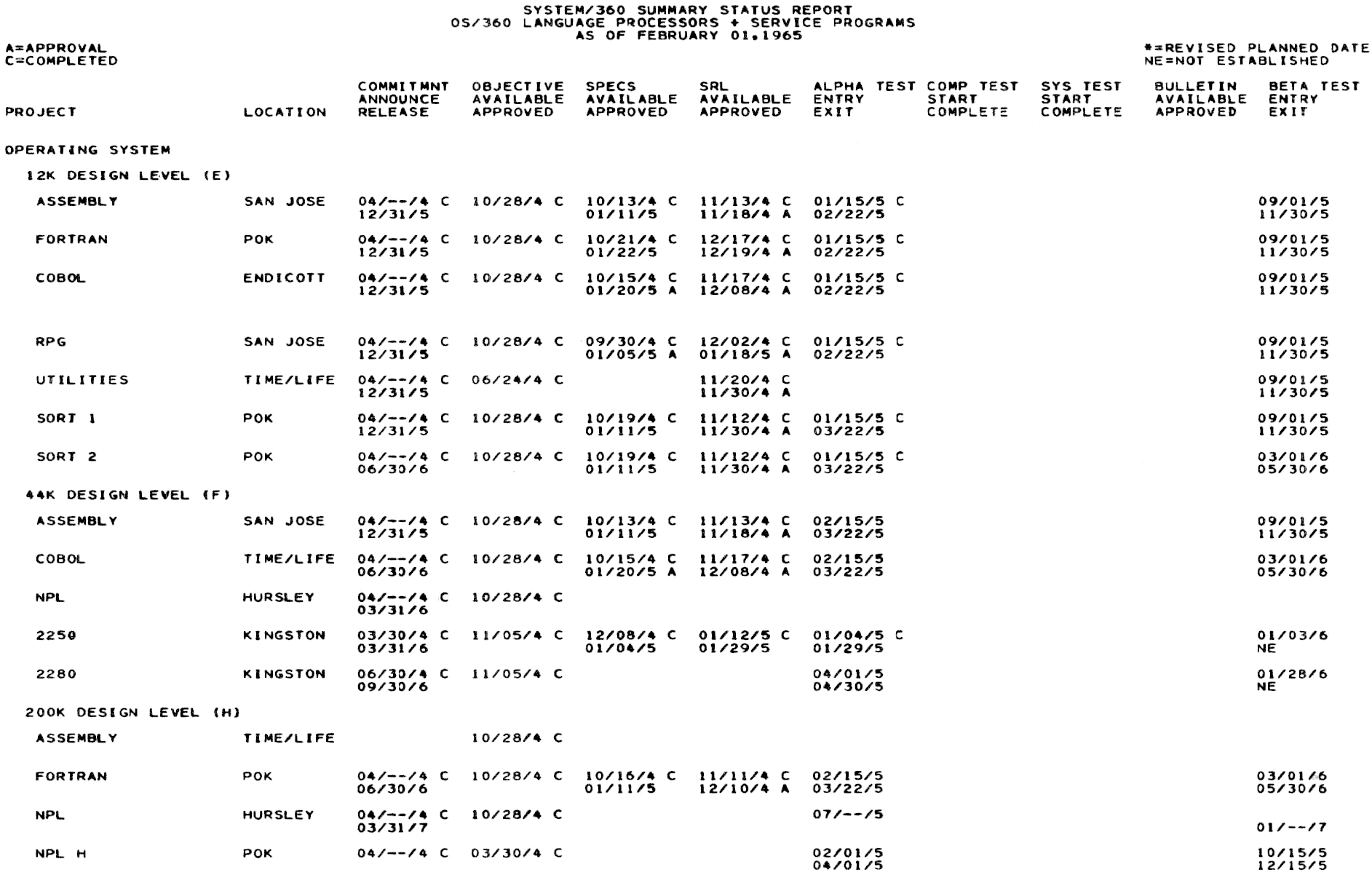
Figure 3.1 – PERT chart from Brooks’ work on the IBM 360 in 1965. Source: Brooks 1979 [1995], p. 159.
The second major concern of Brooks’ book is organization. In this he favours a strong hierarchy. The recommended team organization is what is known as a chief programmer team, though Brooks calls it the “surgical team”. In this, the team consists of a chief programmer and his subordinate right hand, who together do all the actual programming on the project. They are supported by up to eight other people who do various technical and administrative tasks. According to Brooks, it is only possible to develop a coherent system if the number of people that contribute to the design is limited. The central idea of the chief programmer team is thus that it is an organization that allows a lot of people to work on the project in supporting roles while making sure that only the chief programmer contributes to the design.
Brooks also discusses how to organize the highest layer of project management. He maintains that it is extremely important to separate technical and administrative executive functions. He likens the technical manager to the director of a movie, and the administrative manager to the producer. Various possibilities for dividing the power between the two are considered, and Brooks finds that it is best if priority is given to the technical role, so that the technical manager is placed over the administrative manager, at least in projects of limited size. This arrangement mirrors the recommended organization of the chief programmer team, where a programmer is similarly placed in charge of administrative personnel.
In relation to technical issues, Brooks devotes some space to recommendations for trading off computation time for machine memory space, so that one has programs that are slower but also takes up less space. This was a sensible decision at the time. Nowadays, the decision it not so simple, but the choice between having either fast programs or small programs is ever relevant. Other than this, Brooks recommends that the machines and programs that are used during development are of the highest quality, and he lists some categories of programs that are useful in the programming work.
Regarding development methods, Brooks advocates top-down design, structured programming and component testing, as methods to avoid mistakes in the programming. Top-down design amounts to making a detailed plan for the system as a whole before beginning to design the individual components. Structured programming means enforcing a certain discipline in the programming in order to avoid common programmer mistakes and to make it easier to understand the programs. Component testing means testing each piece of the program separately before trying to see if the system as a whole works.
An interesting aspect of Brooks’ work is that he appeals to Christian ontology to justify some of his fundamental assumptions. It is quite important in Brooks’ argumentation to emphasize that programming is creative work, and the inherent creativity of humans is explained as a consequence of man being created in God’s image.4 He views communication problems as the root cause of problems in programming projects, and the problems are explained as analogous to the Biblical story of the Tower of Babel,5 which he calls “the first engineering fiasco.” And we receive a hint of a justification for the central idea of the of the chief programmer team as he states, “A team of two, with one leader, is often the best use of minds. (Note God’s plan for marriage.)” 6
The interesting thing about these appeals to Biblical authority is that they connect Brooks’ thinking to the mainstream Christian intellectual tradition of the Western world. This is in contrast to most contemporary literature in software engineering, where the fundamental ideas about humanity are drawn from disciplines such as psychology and sociology, which have a distinctly modernistic approach to ontology.
1 Brooks 1975 [1995] preface. Patterson & Hennessy 1997 pp. 525–527.
2 Brooks 1975 [1995] p. 153.
3 “The technology, the surrounding organization, and the traditions of the craft conspire to define certain items of paperwork … [the manager] comes to realize that a certain small set of these documents embodies and expresses much of his managerial work. The preparation of each one serves as a major occasion for focusing thought and crystallizing discussions that otherwise would wander endlessly. Its maintenance becomes his surveillance and warning mechanism. The document itself serves as a check list, a status control, and a data base for his reporting.” Brooks 1975 [1995] p. 108.
4 Brooks 1975 [1995] p. 7.
5 Ibid. p. 74, p. 83.
6 Ibid. p. 232. The original has square brackets instead of parentheses.
3.1.3 Process thinking
A prominent characteristic of the way in which software engineers think about development processes is that the process is divided into a number of distinct phases that follow each other. The exact number of phases varies between authors, though they usually follow a general trend. At the beginning of development is a phase where the problem is specified, followed by a phase of high level design, often called architecture. Then follows more detailed design, then coding, and finally testing, and actual use of the program.
The phases that have to do with specification, program architecture, and design clearly correspond to the design process in ordinary engineering. According to Vincenti, the historian of aeronautics engineering, the ordinary engineering design process consists of:1
-
1. Project definition.
-
2. Overall design.
-
3. Major-component design.
-
4. Subdivision of areas of component design.
-
5. Further division of categories into highly specific problems.
This process mirrors the software development phases, in which the activities also start with specification and definition, after which they progress to design phases that are at first very general, and continue with phases of more and more detailed design.
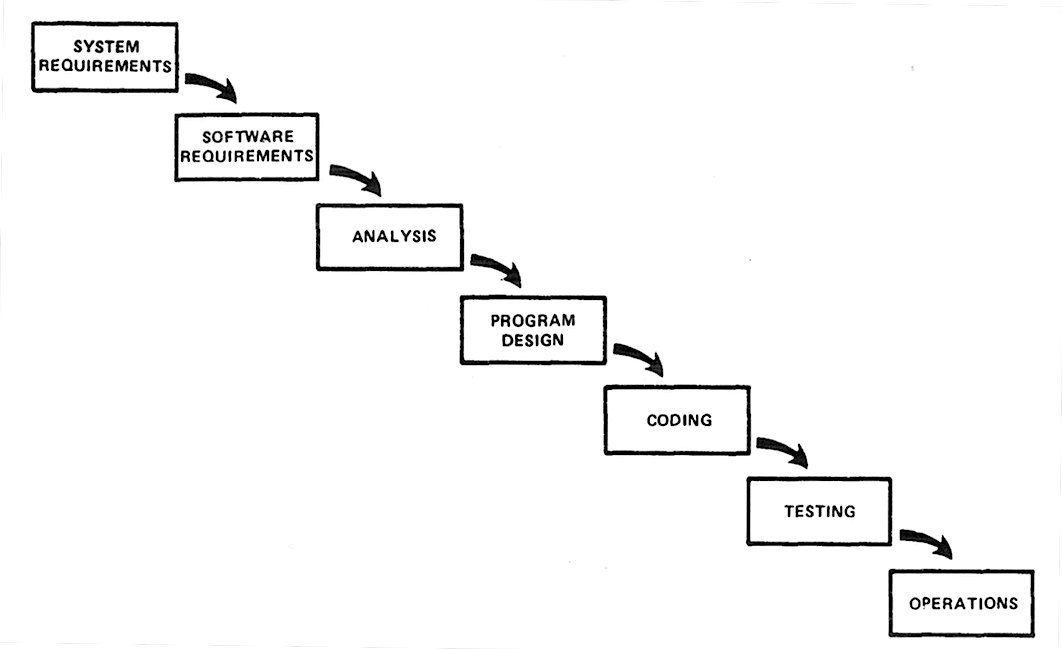
Figure 3.2 – The waterfall model: “Implementation steps to develop a large computer program for delivery to a customer.” Source: Royce 1970, fig. 2, p. 329.
The idea of a distinct testing phase that follows the design and coding phases also corresponds to an ordinary engineering notion of testing. In ordinary engineering, the testing phase naturally follows after design and building phases; it is impossible to test something that has not yet been built. This leaves the coding phase as the only phase that is distinct to software engineering. It is often likened to a construction or building phase in ordinary engineering.
Process thinking in software engineering can be considered to revolve around two fundamental concepts: phases, and how to get from one phase to the next. Boehm writes: “The primary functions of a software process model are to determine the order of the stages involved in software development and evolution and to establish the transition criteria for progressing from one stage to the next.” 2
The transition criteria to which Boehm refers are what are variously called “documents”, “work products”, or “artefacts”. These are generally documents, in the usual sense of the word, but they can also be other kinds of work material in written form, for example source code or test result listings.
The best known model of software development by far is the so-called “waterfall” model, in which the phases of software development are arranged in a strict sequence such that one phase is completely finished before the next begins. In 1970 Winston W. Royce published an article describing this model, based on his experience of developing software for spacecraft missions. Royce’s version of the waterfall model can be seen in Figure 3.2. The model has gained its name from the way the boxes and arrows in the picture resemble the flow of water in a waterfall.
It should be noted that Royce neither intended the model to be descriptive of how software development actually happens, nor considered it realistic to have such a simplistic model as the goal for how development should be done. However, the model does reflect a conception of how programming would be “in an ideal world”, if it were not hampered by the imperfections of people. Thus, many software models that are more complicated, and meant to be more realistic, are essentially embellishments upon the waterfall model. Note also that Royce did not think the model necessary at all for small programs – it is only intended for large projects.
The “V-model” is closely related to the waterfall model, but places much more emphasis on the testing of the program. Instead of having a single test phase, as in the waterfall model, the test phase is separated into a number of test phases, each corresponding to one of the design phases of the waterfall model. The V-model gained its name because of its shape: a version can be seen in Figure 3.3. This model plays an important role in safety critical programming; we shall therefore return to it in Chapter 5 (Safety critical programming).
1 Vincenti 1990 [1993] p. 9.
2 Boehm 1988 p. 61.
3.1.4 Systems thinking
Software engineering thinking is often preoccupied with the administrative aspects of management; that is, with planning, documenting and evaluating. The general interest of software engineering is in large, complex projects that need to be managed intensively.
An example is the “spiral model” of software development, published by Boehm in 1988 while he was working for the TRW Defense Systems Group. The model came about after Boehm’s attempts to apply the waterfall model to large government projects, when he realized that projects do not proceed from start to finish, as in the waterfall model, but rather in a number of iterations of the project phases.1
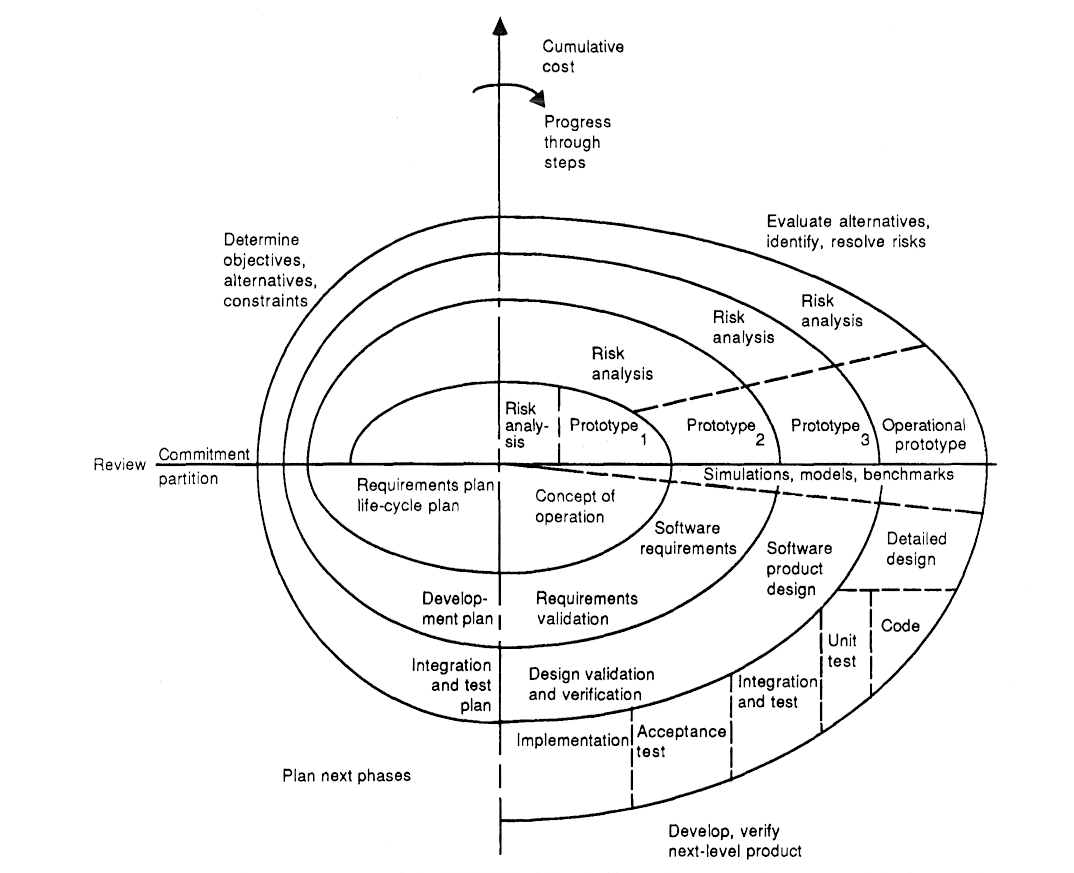
The spiral model is shown in Figure 3.4. The waterfall model is embedded in the lower right quadrant of the spiral model, where we find all the phases of the waterfall model: specification (“requirements”), design, coding, testing, and operating (“implementation”). The prototype, simulation and benchmark phases in the model are somewhat optional.2 Apart from the lower right quadrant, the largest part of the model is therefore concerned with administrative management: activities that concern documentation and planning (requirements planning, development planning, integration planning, commitment review, determining objectives, risk analysis and evaluation).
Robert Grady of the Hewlett-Packard Company has taken the emphasis on administrative management even further. In a 1997 book about software process improvement, he presents a model that is essentially a copy of Boehm’s spiral model. Grady’s model, shown in Figure 3.5, is entirely removed from programming practice. Instead, it is oriented towards company organization and the bureaucracy needed to maintain a sizeable organization – which chiefly involves documentation, training, standardizing, and gaining company-wide support.

The Rational Unified Process is a process model currently promoted by IBM. It was originally created by Grady together with Ivar Jacobson of the telecommunications company Ericsson and James Rumbaugh of General Electric. The so-called “process structure” of the model can be seen in Figure 3.6.
We recognize the usual phases of the waterfall model: requirements, design, implementation (coding), test and deployment – except now they are termed “workflows”, and supplemented with a few more, such as business modelling and project management. The workflows are executed concurrently in four phases, and each phase consists of a number of iterations. The irregular shapes in the diagram show the approximate intensity of each workflow in each of the iterations.
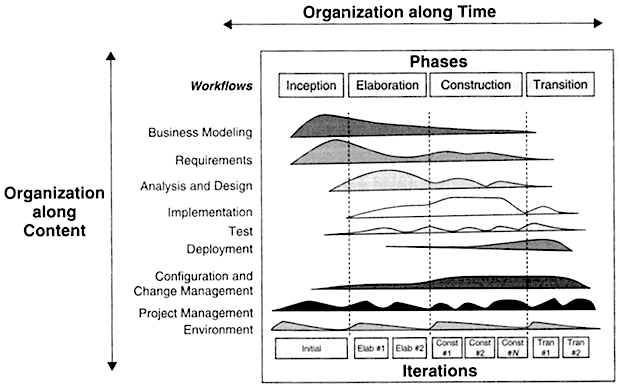
As is apparent, the diagram in Figure 3.6 is not of great practical use on its own. It has to be supplemented by a wealth of other diagrams, and the Rational Unified Process is arguably not meant to be used without a large number of computer programs that support working with it, developed by IBM. It is a complicated model, meant for projects with complex administration.
We can now begin to see why software engineering thinking is so preoccupied with documents. A process model, in Boehm’s words, consists of a number of stages arranged in order, along with transition criteria for moving from one stage to the next. Documents are important because they serve as transition criteria. When a document has been produced and approved, the process can move to the next stage and development can progress.
An extension of this way of thinking is to regard documents as input and output to the stages. The ”input” documents are those that need to be approved before the stage begins. The ”output” documents are those that have been produced when the stage has ended.
As previously noted, documents are often called work products or artefacts, and they are not restricted to be documents in the usual sense, but can also, for example, be the source code for programs. The most important aspect of a document in this sense is that it serves as a transition criterion that is tangible and can be checked. Thus the purpose of an individual document is not regarded as its most significant trait – executable code, structure diagrams and budget plans are all work products, regardless of their widely differing purposes.
If we turn our attention to the planning side of software engineering, we find that the documents that serve as criteria have a temporal counterpart: namely, milestones. Milestones are the dates that separate phases from each other. When the documents that are associated with a given milestone have been approved, the milestone has been cleared and the project can progress.
The dominant trend of project management within software engineering is thus concerned with meeting the appropriate milestones by completing the required phases to produce the associated documents. This is ensured by allocating sufficient resources to each phase. Resources can be material things, such as machines, but they are first and foremost qualified personnel. A common way of administrating milestones, phases and resources is by way of the so-called Gantt chart, shown in Figure 3.7, which is a variant of the PERT method espoused by Brooks (Figure 3.1).
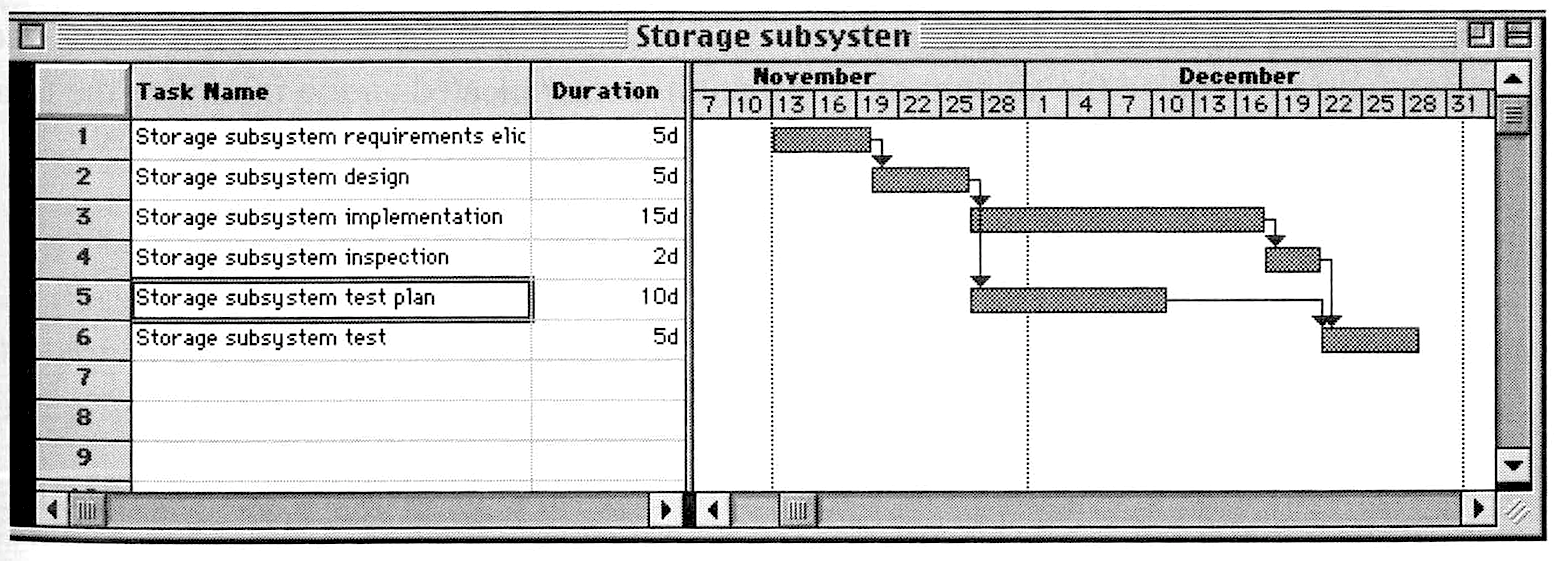
The Gantt chart shows the various tasks belonging to a project phase and how they are connected. By estimating how long each task will take and how many resources it requires, the Gantt chart allows the engineers to compute the completion date of each milestone and hence the time when the project documents will be finished. If a task is delayed, it will push back all subsequent tasks that depend on it, with the result that the whole project is delayed. When the final milestone has been met, the project is finished.
1 Boehm 1988 p. 64.
2 Boehm 1988 p. 65.
3.1.5 Requirements engineering
The requirements, or specification, of a software project tell programmers and managers what the users, or buyers, want the software to do. The requirements are thus of singular importance to a project – how could it be possible to make a program if one were not aware of what it is supposed to do? Important as they are, specifying the requirements brings about a host of problems, for, in Brooks’ words, “the hardest single part of building a software system is deciding precisely what to build.” 1
Consequently, requirements engineering is a subfield of software engineering concerned with requirements. The most obvious approach to deciding what to build is simply to ask the intended users what they want. However, this is rarely sufficient in practice, says Brooks, “for the truth is, the clients do not know what they want.” 2 A common approach when the users have stated what they think they want is to try to separate the “what” into two questions: “why” they want it, which becomes their business goals; and “how” it can be achieved, which is a technical problem for the engineers to solve.3
If we look at the software engineering process models, we see that requirements are generally relegated to a separate phase in the beginning of the process (with the exception of the Rational Unified Process, in which requirements are a separate workflow). The ideal is that, first, the requirements are discovered and carefully written down in a requirements specification, after which the development can proceed unhindered by doubts about what the system is really supposed to do.
However, this ideal of separating the requirements specification from the rest of the development process is just that – an ideal – and it is seldom met in practice. C.A.R. Hoare, in his 1980 Turing Award Lecture, stated that “the design of a program and the design of its specification must be undertaken in parallel by the same person, and they [the designs] must interact with each other.” 4 In the original article describing the waterfall process, Royce states that: “For some reason what a software design is going to do is subject to wide interpretation even after previous agreement.” 5
When writing a requirements specification, it is of fundamental importance that the software engineer has sufficient understanding of what the user is trying to do. Otherwise, the requirements will express what the user literally says, but not what the user wants. This kind of knowledge of the user situation is commonly called “domain knowledge”.6 It is often contrasted with software engineering knowledge, or programming knowledge, which is knowledge about how to make the programs that is implicitly supposed to be independent of the domain in which the program is to work.7
In accordance with the general software engineering focus on documents, the literature on requirements engineering devotes much attention to notation systems and formats for writing things down. For example, Søren Lauesen’s 2002 textbook on requirements engineering describes writing down requirements in the form of state diagrams, state-transition matrices, activity diagrams, class diagrams, collaboration diagrams, and sequence diagrams. Not surprisingly, most of these forms of diagrams are originally made for program design and thus meant to describe computer programs.
1 Brooks 1986 [1995] p. 199.
2 Ibid.
3 Lauesen 2002 p. 29.
4 Hoare 1980 [1981] p. 79.
5 Royce 1970 p. 335.
6 Lauesen 2002 p. 20.
7 Ibid. p. 26.
3.2 Agile software development
3.2.1 The origins of the Agile movement
The concept of Agile software development refers to a very diverse set of approaches, whose underlying philosophies loosely share common themes. The software engineering approaches, as described in Section 3.1 above, are to a large degree institutionalized in university departments, professional associations, well-defined processes and standards, and so on. In contrast, the Agile movement is less organized, making it difficult to specify exactly what is Agile and what is not. Approaches that are “outside” the movement are also sometimes considered Agile so long as they share the same basic attitude to development.
The basic characteristics of Agile methods is that they focus on rapid change and “lightweight” processes. This contrasts with the traditional software engineering focus on “heavyweight” processes and “plan-driven” development. The Agile movement emerged among programmers who were familiar with software engineering thinking, and thus Agile development is both derived from software engineering and formed in opposition to it. Understanding this tension within Agile thinking is important for understanding the underlying philosophy.
The Agile movement started well before it gained its current name. For example, the influential book Peopleware1 (1987) brought to light a focus on the importance of teamwork that is central to many Agile methodologies, and during the 1990s Agile methodologies such as Dynamic Systems Development Methodology and Extreme Programming were developed. The movement gained its name in 2001, when a group of influential software professionals collaborated on the Agile manifesto, in which they agreed on some core principles of their very different methodologies.
Before the publication of the Agile manifesto, the movement received little attention and was, in general, not taken seriously within academia and software engineering.2 Although the movement gained more acceptance and interest from 2001, it continued for some years to hold academic conferences separately from mainstream software engineering.3 However, by 2014 Agile development has become successful, as large companies such as the telecommunications firm Ericsson are seeking to become more agile.4 As with all successful movements, claiming to be “agile” has now become fashionable.5
2 E.g.: “ … academic research on the subject is still scarce, as most of existing publications are written by practitioners or consultants.” Abrahamsson et al. 2002 p. 9.
3 “In a short time, agile development has attracted huge interest from the software industry. … In just six years the Agile conference has grown to attract a larger attendance than most conferences in software engineering.” Dybå & Dingsøyr 2008 p. 5.
4 Auvinen et al. 2006: “Software Process Improvement with Agile Practices in a Large Telecom Company.”
5 This has prompted parodies such as “Manifesto for Half-Arsed Agile Software Development”, which pokes fun at enterprise companies’ reluctance to commit to Agile values despite embracing the terminology.
3.2.2 The Agile manifesto
The Agile manifesto1 is shown in Figure 3.7. It consists of four pairs of values, where each pair has a preferred value. After that follows 12 principles that give some methodological consequences of the values. It is clear that the values and principles as they are written are open to different interpretations – the creators intended it that way. This means that the manifesto alone is not enough to understand Agile practices.
The Manifesto for Agile Software Development
Seventeen anarchists agree:
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
Individuals and interactions over processes and tools.
Working software over comprehensive documentation.
Customer collaboration over contract negotiation.
Responding to change over following a plan.
That is, while we value the items on the right, we value the items on the left more.
We follow the following principles:
-
• Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
-
• Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
-
• Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
-
• Business people and developers work together daily throughout the project.
-
• Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
-
• The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
-
• Working software is the primary measure of progress.
-
• Agile processes promote sustainable development. The sponsors, developers and users should be able to maintain a constant pace indefinitely.
-
• Continuous attention to technical excellence and good design enhances agility.
-
• Simplicity–the art of maximizing the amount of work not done–is essential.
-
• The best architectures, requirements and designs emerge from self-organizing teams.
-
• At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behaviour accordingly.
—Kent Beck, Mike Beedle, Arie van Bennekum, Alistair Cockburn, Ward Cunningham, Martin Fowler, James Grenning, Jim Highsmith, Andrew Hunt, Ron Jeffries, Jon Kern, Brian Marick, Robert C. Martin, Steve Mellor, Ken Schwaber, Jeff Sutherland, Dave Thomas
www.agileAlliance.org
Figure 3.7 – The Agile manifesto. This is the version published in Dr. Dobb’s Journal. Fowler & Highsmith 2001.
For example, the phrase “we value individuals and interactions over processes and tools” can be interpreted in a number of ways. This does not mean that tools can be ignored; some methodologies place great emphasis on tools. In Extreme Programming, for example, tools for automated testing and version control are important. Rather, the sentence says something about the way tools should be used.
By referring to themselves as anarchists (“Seventeen anarchists agree … ”), the creators of the manifesto show that they are conscious of a break with mainstream software engineering traditions. At the same time they are hinting that the Agile movement is a diverse and non-dogmatic movement.2
The break with tradition is also seen in the way in which the core Agile values – individuals and interactions, working software, customer collaboration, responding to change – are contrasted with what can be considered the foundational values of software engineering: processes and tools, comprehensive documentation, contract negotiation and following a plan. However, the creators do not dismiss the traditional software engineering values: on the contrary, they acknowledge their worth (“ … while we value the items on the right … ”). Thus, they are not only conscious of a break with tradition, but also of having their roots within that tradition and of being indebted to it.
1 The manifesto was published on the Agile Alliance’s website in 2001. Dr. Dobb’s Journal also published it online in August 2001 with comments by Martin Fowler and Jim Highsmith. An edited version with comments is published as an appendix in Cockburn 2001.
2 The story about being diverse and non-dogmatic is repeated in the comments to the manifesto, in which the creators stress that they are “fascinated” that they could agree on anything. Fowler & Highsmith 2001. They also “hoped against hope” that they could agree on something. Cockburn 2001 p. 177.
3.2.3 Scrum as an example
It is easier to understand the reasoning behind Agile through a concrete example than through discussing the Agile values in the abstract. We will therefore take a look at the Scrum methodology, a well-known Agile methodology that was developed principally by Ken Schwaber and Jeff Sutherland during the 1990s.1 The word “Scrum” itself comes from rugby football; it means that all players huddle together around the ball to restart play following an interruption.
There are three roles in a Scrum project, and anyone that is not in one of these three roles is regarded as a spectator or an interested party without direct authority. The roles are: Product Owner, ScrumMaster, and Team.
The Product Owner is the representative of the customers or the users of the software. It is his responsibility to provide the Team with a list of features to implement, to take business decisions, and to prioritize the features for the Team so that they know what they should work on first.
The ScrumMaster is responsible for ensuring that the Scrum process is being followed. The ScrumMaster is the representative of the Team and acts in the Team’s interest to make sure that it has the necessary conditions needed for doing the work. The ScrumMaster is also responsible for teaching the Product Owner how to use the Scrum process to get the maximum business value from the Team’s work. The ScrumMaster role can be filled by anyone except the person acting as Product Owner.
The Team comprises the people doing the work. The optimal Team size is around seven persons: if the Team is many fewer than seven, Scrum is not needed; if there are many more, it is best to organize them in several Teams working together on a project. The Team must be composed of competent individuals and there is no hierarchy of authority within it. The Team manages its work itself with the help of the input it gets from the Product Owner, and no one outside the Team can dictate its work – not even the ScrumMaster.
The team works in periods of 30 days, called Sprints. Before each Sprint, the Team meets with the Product Owner, who presents the work he would like to be done and prioritizes it. The Team then selects an amount of work that it thinks it can handle within one Sprint and commits to doing it. After the Sprint, the team again meets with the Product Owner and other interested parties and presents all the work it has completed during the last Sprint. The Team and the Product Owner plan the following Sprint based on what the Product Owner now thinks are the most important features.
Before starting a new Sprint, the Team also holds a meeting in which it reviews the previous Sprint and assesses whether the working process has any problems and whether it can be improved. This Sprint review meeting is the main mechanism for continuous process improvement in Scrum.
During each Sprint, the Team holds a 15-minute Scrum meeting every day. Each member answers three questions: What have you worked on since last meeting? What will you work on until next meeting? Are there any hindrances to your work? Only the Team members and the ScrumMaster are allowed to talk during the Scrum meeting.2 Other people can observe, but they must remain silent.
These are the basic rules of working with Scrum. The complete set of rules runs to a mere seven pages.3 Thus, the rules necessarily leave many practical questions unanswered. Scrum does not provide detailed rules for how the Team should work; rather, it provides a basic framework of rules. This means that in order to apply the Scrum rules correctly, one has to know why they are there. Scrum is built on three core principles: transparency, inspection, and adaption. All of the rules and practices of Scrum are designed to facilitate one or more of these three principles; if a rule is used in a way that goes against the principles, the Scrum process does not work as intended.
For example, Schwaber describes a Team that was following the letter of the Scrum rules, but was “hiding” behind task descriptions that were so abstract that it was not possible to tell how much work was actually required to complete the tasks.4 Thus, the Team violated the principle of transparency, which dictates that all relevant information must be clear and accessible to everyone involved. In turn, the violation of the transparency principle meant that the team lost the ability to follow the other principles, inspection and adaption. Thus, while the letter of the rules is not always important in Scrum, even a small deviation from the core principles can have a detrimental effect on the project.
My own interpretation of Scrum is that the methodology is, on one hand, oriented towards the practical day-to-day tasks of development. On the other hand, it rests on a subtle but coherent philosophical system that means that the details of the methodology must be understood and cannot be changed haphazardly. The philosophical system in turn rests on a certain work ethic. Scrum demands that the Team members have an attitude to their work that is consistent with the underlying values and principles of the methodology.
1 The presentation in this section is based mainly on Ken Schwaber’s 2003 book, Agile Project Management with Scrum.
2 In principle, also the Product Owner.
3 Schwaber 2003, Appendix A. For comparison, the software engineering DOD-STD-2167 Military Standard for Defense System Software Development is 90 pages long – U.S. Department of Defense 1985. The software requirements for the safety critical engineering process IEC 61508-3 are 112 pages long – International Electrotechnical Commission 2009.
4 Schwaber 2003 p. 96 ff.
3.2.4 Programming practice
As discussed above, the Agile movement consists of a host of different approaches. Some of the approaches considered to be Agile are Extreme Programming, Adaptive Software Development, Feature-driven Development, Dynamic System Development Methodology, Lean Development, Adaptive Software Development, Scrum, and the Crystal methodologies.1 There are also approaches that, even though they are not part of the Agile movement as such, can be considered Agile in their spirit, either because they have influenced the Agile movement or because they are similar in their practices to Agile methodologies.
The 1987 book Peopleware is not a development methodology, but the authors wrote about the importance of teamwork and self-organization in software development, themes that are central to Agile methodology, and their ideas have influenced later Agile approaches.2 The popular weblog writer Joel Spolsky has developed a “Joel Test” of 12 easily checked, practical working conditions, which can be said to embody many of the same values as Agile development.3 Andrew Hunt and David Thomas are both co-creators of the Agile manifesto, though they “have no affiliation to any one method.” 4 Their influence is through the book The Pragmatic Programmer which, as the title suggests, contains practical advice on a fairly concrete level.5
Thus, there is a large diversity within the Agile movement. The same ideas are often found in methodologies that otherwise differ quite considerably, and the sources of inspiration for the Agile methodologies are varied, even eclectic. These aspects of the Agile movement are all due to the fact that Agile is very much grounded in programming practice. Programming practice develops with its own local particularities and quirks, and this is reflected in the Agile movement.
To an extent, Agile is based on common sense, on what the programmer would do in any case – at least, this is how the Agile movement sees itself. In the words of the Agile practitioner Jim Coplien: “Everyone will like Scrum; it is what we already do when our back is against the wall.” 6 Schwaber relates a story about a product manager that applies Scrum, not in the form of the usual rules, but in the form of simple common sense.7
The emphasis on practicality and common sense has some consequences in practice that distinguishes the Agile movement from software engineering. For example, as we saw in Section 3.1.2, Brooks took the documentation for a project to be the starting point for thinking about how it should be managed, stating that five formal documents should form the basis for all management decisions.
In contrast, Alistair Cockburn repeatedly stresses that documentation merely has to be good enough for its purpose, and how good this is always depends on the situation.8 In many situations the important information is best conveyed in person, and a formal document would be superfluous, even undesirable. This is a pragmatic approach that, in each particular situation, takes into account what the purpose of the documentation is.
As we saw with Scrum in Section 3.2.3, Agile methodologies rest partly on an underlying philosophical system and partly on principles that derive from concrete programming practice. Each Agile methodology contains a particular mix of philosophy and development practice. Scrum is quite explicit about its core values, without becoming a treatise on philosophy. On the other hand, Extreme Programming is very much based on concrete practices, and demands that programmers always work together in pairs, that all program code is tested every day, and that everyone is sitting in the same room or building – things that the more abstract rules of Scrum leave up to the developers themselves.
In general, Scrum instructs people how they should work, not what they should do in their work. What they concretely have to do is something they have to know already – it stems from their previous experience, their tacit knowledge, and their culture.9 This necessary pre-existing experience and ability is treated differently by the different Agile methodologies. Extreme Programming, for example, is more particular about “engineering excellence” than is Scrum.10
Scrum can be summed up as a project management philosophy that is based primarily on programming practice instead of on software engineering theory. To some extent, this is true of all Agile methodologies.
1 See Beck & Andres 2004; Fowler & Highsmith 2001; Highsmith 2002; and Cockburn 2001.
2 DeMarco & Lister 1987. For Peopleware’s influence on Agile methods, see for example Cockburn 2001 p. 56, p. 80.
3 Spolsky 2004 chp. 3. First published online August 2000.
4 Cockburn 2001 p. 177.
6 Schwaber & Sutherland 2010 p. 2.
7 Schwaber 2003 p. 60.
8 Cockburn 2001 p. 18, p. 63, p. 147 f.
9 Cockburn in particular points to the importance of the developers’ culture. Cockburn 2001 p. 30, p. 55, p. 92. Developers’ knowledge of programming is part of their culture, among other things.
10 Schwaber 2003 p. 107.
3.2.5 Work ethics
Just as the philosophical foundation of Scrum rests on a certain work ethics, Agile methodologies require that participants care about their work, and that they care about it in a certain way. Doing a good job is its own reward, and to be able to help other people out is the highest purpose of a job well done.
Ken Schwaber writes of a company that he helped to implement Scrum:
“When I last visited Service1st, it was a good place to visit. I could watch people striving to improve the organization, the teams, themselves, and their profession. I was proud to be associated with them. … What more can you ask from life?” 1
The quote expresses the sentiment that the work ethic – striving to improve – is the most important part of the changes brought about by Scrum, and that merely being associated with these working people is reward enough for Schwaber.
The opening sentence of Jim Highsmith’s explanation of Agile development is a quote from a project manager: “Never do anything that is a waste of time – and be prepared to wage long, tedious wars over this principle.” 2 This stresses that Agile methodologies are not for people who do not care for their work, or who take the path of least resistance; and it indicates that to uphold certain work ethics comes with a cost. Agile practices can be difficult to implement because the benefits come with hard choices.
Alistair Cockburn writes of the kind of people whom Agile methodologies aim to encourage: “Often, their only reward is knowing that they did a good deed, and yet I continually encounter people for whom this is sufficient.” 3 He relates a story of the teamwork in a hugely successful project: “To be able to get one’s own work done and help another became a sought-after privilege.” 4
In The Pragmatic Programmer a similar attitude to caring about one’s work is displayed:
“Care about your craft. We feel that there is no point in developing software unless you care about doing it well. … In order to be a Pragmatic Programmer we’re challenging you to think about what you’re doing while you’re doing it. … If this sounds like hard work to you, then you’re exhibiting the realistic characteristic. … The reward is a more active involvement with a job you love, … ” 5
The Agile movement is, of course, not alone in having an ethical foundation. Software engineering, for example, is founded on a professional ethic, which is directed less toward the work being its own reward, than toward upholding a professional community. The core values of the software engineering ethic are: to be rigorous, to be scientific, and to do good engineering.
In Scrum, the value of working in a certain way is only justified by the value of the outcome. To work according to scientific principles, for example, is only valued if the situation calls for it. The rules of Scrum are really an insistence on the absence of unnecessary rules. Ideally there would be no rules – only competent, cooperating individuals with common sense. However, since rules cannot be avoided altogether, the rule set at least has to be minimal, such that if someone tries to impose new rules, one can reasonably object “that’s not Agile!”
The consequence of the Scrum rule set is to give executive power to the programmers. They determine how to do their job, and it is the ScrumMaster’s task to ensure that no one interferes with them. Fittingly, Schwaber likens the ScrumMaster to a sheepdog, so the ScrumMaster should not really be seen as a master who commands, but more as one who serves and protects his flock.6
The Agile insistence on giving the programmers executive power parallels Brooks’ advocacy of placing them at the top of the decision-making hierarchy (see Section 3.1.2). However, while Brooks’ model has never really caught on, Scrum has enjoyed widespread success. The main reason is probably that with Scrum, the programmers’ power is strictly delimited. They reign absolutely, but only over their own work process. The Product Owner has a clear right and mechanisms to decide what they should work on, and holds frequent inspection meetings to see that his wishes are carried out.
In Scrum, along with the power to decide over their own work, the programmers also receive the full responsibility of organizing themselves, alongside the demand that they are mature enough to do this. For this reason, the organization of a team of peers without formal hierarchy is an important part of Scrum. In Agile thinking this is a central concept, called self-organization.
Agile methodologies are advertised by their proponents as being more efficient and delivering more value. However, in Agile thinking the efficiency is a consequence of the ethics: it is not that the most efficient system was found, with an ethical part added as an afterthought. Non-Agile methodologies can be efficient, but if their ethics are very different, the results of their efficiency will be different as well.
1 Schwaber 2003 p. 118.
2 Highsmith 2002 p. 4.
3 Cockburn 2001 p. 63.
4 Dee Hock, 1999, on the first VISA clearing program. Quoted in Cockburn 2001 p. 64.
5 Hunt & Thomas 1999 p. xix f.
6 Schwaber 2003 p. 16.
3.2.6 Relationship to software engineering
As discussed above, the Agile methodologies are both derived from software engineering and developed in opposition to it. Proponents of Agile methodologies sometimes downplay this opposition in order to make their methodologies more palatable to traditional software engineers.

Figure 3.8 – “The evolution of the Waterfall Model (a) and its long development cycles (analysis, design, implementation, test) to the shorter, iterative development cycles within, for example, the Spiral Model (b) to Extreme Programming’s (c) blending of all these activities, a little at a time, throughout the entire software development process.” Source: Beck 1999.
For example, Kent Beck, one of the creators of Extreme Programming, pictures a continuous evolution that proceeds as a matter of course from the earliest software engineering model, the waterfall model (see Figure 3.2), over iterative development, and ending in Extreme Programming.1 Beck’s illustration of this evolution is depicted in Figure 3.8. With this evolutionary model, Beck is portraying his Agile methodology as a continuation of software engineering practices, and stressing the commonality between software engineering and the Agile movement.
The evolutionary model conceals the philosophical differences between software engineering and the Agile movement. Seen from the perspective of the underlying philosophy, Agile is not so much a gradual change in tradition as it is a radical shift in thinking.
Nevertheless, Agile has clear ties to the engineering tradition of software engineering and this is an important part of the movement’s self-perception. Both Schwaber and Highsmith conceptualize the difference between Agile and software engineering’s plan-driven methods as being between “empirical processes” and “defined processes”.2 The concepts of empirical and defined processes come from chemical engineering process theory.3
The Lean approach to development has even stronger ties to traditional engineering, because it was originally developed in the Toyota Production System for car manufacturing in the 1980s. The system was later adapted to an Agile software methodology, primarily by Mary and Tom Poppendieck.4
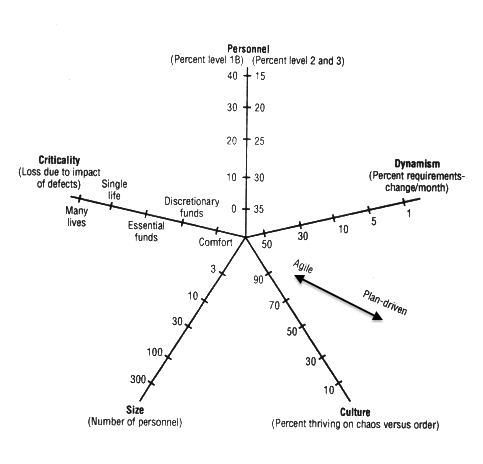
As the popularity of Agile methodologies has grown, so has the interest from software engineering researchers in explaining these methodologies in software engineering terms. One example of this is a model proposed by Boehm and Turner in the 2003 article “Using Risk to Balance Agile and Plan-Driven Methods”. This model, shown in Figure 3.9, essentially presents Agile and plan-driven methods as two alternatives, with the choice between them depending on five factors. Three of the factors are in reality matters of opinion rather than factual assessments.
One of these three factors is whether the personnel “thrives on chaos”. This is a statement so vague that it cannot be assessed factually. The second is what proportion of requirements changes per month. Requirements change can be measured, but measuring lines changed, number of features changed, or estimates changed, will result in different figures – and in the case of measuring estimates, the measure in practice becomes guesswork. The third factor is the competence of the personnel, but again, the percentage that is “able to revise a method, breaking its rules to fit an unprecedented situation” 5 is a criterion so vague that it becomes a matter of opinion.
That leaves two factual factors: the number of personnel, and the criticality of the software. It is indeed the case that, generally speaking, larger and more critical projects require a larger bureaucracy. Cockburn’s Crystal family of methodologies is an Agile attempt to address these points.6 However, to make the choice of methodology a matter of size, as Boehm and Turner do, is to overlook the fundamental differences in philosophy between Agile and software engineering thinking. From an Agile point of view, the answer to larger projects and bureaucracy is to make the bureaucracy more Agile – not to discard the philosophy in favour of a software engineering model.
The traditional software engineering focus on planning and documentation is not surprising regarding the history of computer use. Computers were first developed in settings that traditionally involved strong bureaucracy and hierarchy: military staff and governmental administration. According to Max Weber, one of the founders of modern sociology, bureaucracy is characterized by making explicit rules and upholding them through the use of well-defined duties, authorities, and qualifications.7 The emphasis on these concepts is apparent in software engineering, where they are often implemented as processes (rules), roles (duties), standards (authority), and certifications (qualifications).
This bureaucratic setting is often in conflict with the fact that programming as an activity is intensely creative. The importance of the creative aspect of programming is noted both by Brooks8 and by Peter Naur,9 famous for his contribution to the Algol 60 programming language and winner of the Turing Award for computer science. If the programmer spends most of his time administrating bureaucratic rules, he will be creative in rule-making, not in programming. The Agile movement can be seen as the creative programmers’ reaction to the bureaucratic traditions of software engineering.
However, the tension between bureaucracy and creativity in programming has deeper roots than the conflict between Agile and software engineering regarding project management philosophy, for the very origins and raison d´être of computers lie in bureaucratic organizations. The bureaucratic origins of programming are thus at odds with its inherent creativity.
As an example of the practical consequences of this tension, we saw in our discussion of systems thinking in Section 3.1.4 that the various documents in a software engineering process are, in principle, all equal. From a bureaucratic point of view, their value lies in their function as transition markers, which allow the process to proceed to the next step. The actual content of the work products is not irrelevant, but secondary – it is less important, as long as it lives up to the criteria for transition.
By contrast, a core Agile principle is that working, demonstrable program code is the primary measure of success. Other work products only have meaning through their contribution to the working code.10 Thus, in Agile methods, a piece of documentation is usually not produced unless there is a compelling reason to make it. Conversely, in software engineering a piece of documentation will generally be made unless there is a provision in the process to skip it.
The tension between bureaucracy and creativity in programming highlights a fundamental difficulty of software development. Software engineering thinking maintains that software development can and should be equivalent to ordering a car part from a factory.11 From an Agile perspective, software development is a collaboration with the customer, and the customer needs to be involved as much as the programmers. In Chapter 5 (Safety critical programming) we will take a closer look at what software development and car manufacturing have in common in practice.
2 Schwaber 2003 p. 2. Highsmith 2002 p. 4.
3 Schwaber 2003 p. 146.
4 Heidenberg 2011 p. 10 f.
5 Boehm & Turner 2003 p. 60.
6 Cockburn 2001 chp. 6.
7 Weber 1922 [2003] p. 63.
8 Brooks 1975 [1995] p. 7.
9 Naur 1985 [2001] p. 194 f.
10 Cockburn 2001 p. 37.
11 Czarnecki & Eisenecker 2000 p. 1 f.
3.3 Computer science
3.3.1 Science, mathematics, formal systems
Computer science is the most prominent of the academic fields that study computers and programming. It was proposed in 19591 and created as a university field in the U.S. a few years afterwards. Software engineering is sometimes regarded as a subfield of computer science and this is true to a degree, but the two schools of thought rest on somewhat different academic traditions. Until around 1970 most people who had anything to do with programming computers were scientists, mathematicians, or electrical engineers.2 While software engineering has its origins in the intellectual tradition of electrical engineers, computer science is dominated by the perspectives of scientists, who need computations, and mathematicians.
Howard Aiken, who developed some of IBM’s influential first automatic computers, imagined in 1937 that computers would be used for scientific calculation in, for example, theoretical physics; and his idea was to use computers for things that required a great deal of calculation and tabulation, for example numerical differentiation.3 This vision of computers was of specialized machinery for narrow scientific fields, a long way from the general appeal of applications such as spreadsheets and accounting.
In 1981, a programming guide for microprocessors gives laboratory work as an example of what computers might be used for. This is not the specialized scientific calculations envisioned by Aiken, but a practical device that can ease the laboratory worker’s daily life: “There are many applications for division, but one of the most common is in taking the average of a set of numbers – perhaps the results of a series of laboratory tests.” 4
The famous Dutch computer scientist Edsger W. Dijkstra regards programming as a branch of applied mathematics and, at the same time, a branch of engineering. This makes for a neat division of computing into computer science on one hand and various flavours of engineering on the other. The emphasis on mathematics is shared by Lawrence C. Paulson, professor of programming languages, who advocates a form of programming – functional programming – that consists of expressions that obey mathematical laws.5 Functional programming has met with limited success in the programming industries, but has been popular within academia.
For Paulson, the aim of functional programming is to make programs easier to understand by mathematical reasoning.6 In addition, the use of mathematical analysis is said to break bad habits that programmers form through the use of low-level programming languages,7 where “low-level” means that the programming languages have a fairly simple and direct relationship between how code is written and what the computer does.8 In other words, direct manipulation of the machine results in bad habits, and mathematical reasoning is the way to combat this.
Some computer scientists place great emphasis on formal logic and formal systems, and regard these as the essential characteristics of computer science. According to one textbook of logic in computer science:
“The aim of logic in computer science is to develop languages to model the situations we encounter as computer science professionals, in such a way that we can reason about them formally. Reasoning about situations mean constructing arguments about them; we want to do this formally, so that the arguments are valid and can be defended rigorously, or executed on a machine.” 9
The reasoning here is that formal arguments lead to valid arguments that can be defended rigorously. Another example of thinking that is centred on formal systems comes from a textbook in type theory. Type systems is a technique that is used in every modern programming language; and this textbook states that type systems are lightweight formal methods that can be applied even by programmers unfamiliar with the underlying theory.10 To view type systems in this light emphasizes formal systems, in contrast to viewing type systems as a natural development of programmers’ need to keep different kinds of numbers and letters separate from each other.
1 Fein 1959: “The Role of the University in Computers, Data Processing, and Related Fields.”
2 Mahoney 1990 p. 328.
3 Aiken 1964 p. 192 ff., p. 196.
4 Scanlon 1981 p. 117.
5 Paulson 1991 [1996] p. 2 f.
6 Ibid. p. 10.
7 Ibid. p. 12.
8 This does not mean, however, that they are simple to use. Many of the complexities that “high-level” programming languages introduce are things that make the programming task easier for the programmer.
9 Huth & Ryan 2000 [2004] p. 1.
10 Pierce 2002 p. 1.
3.3.2 Algorithms and data structures
The primary study object of computer science are programs and programming languages. Therefore, it makes sense to try to establish how programs are perceived by computer scientists: what do they mean when they speak of a program? The authors of the famous textbook The C Programming Language write that C consists of data types and structured types, mechanisms for fundamental control flow, and mechanisms for separating computation into functions and for separate compilation.1 Schematically, a programming language, and by extension a program, can thus be described as:
structured data
+
fundamental control flow
+
modular mechanisms
Data structures are descriptions of how things, i.e. numbers and text, are placed in the machine memory. Control flow is the mechanism to describe algorithms: an algorithm is a sequence of steps that the computer carries out; it is “what the program does”. The things upon which an algorithm operates are the data. Modular mechanisms tie smaller program modules together into larger programs.
Charles Simonyi, a programmer who is famous for his work on Microsoft Word and Excel, has said that programming is a science, an art, and a trade.2 The science is knowledge of the best algorithms to use; the art the ability to imagine the structure of the code; the trade is knowing the details of writing efficient code.
Bjarne Stroustrup, the creator of the widely used C++ programming language, has written that procedural programming – what he calls “the original programming paradigm” – amounts to the imperative, “Decide which procedures you want; use the best algorithms you can find.” 3 Stroustrup continues: “The focus is on the processing – the algorithm needed to perform the desired computation.” This sums up neatly the perspective of much of classical computer science: it is first and foremost a science of algorithms.
A complementary view is presented by Naur, who places the emphasis not on algorithms but on their counterparts, data structures. For Naur, computer science is simply the description of data and data processes. For this reason, Naur wanted computer science to be called “datalogy” – “The datalogist describes data and data processes in a way similar to how the botanist describes plants.” 4 The name caught on in the Nordic countries, where it is used to this day (in Danish: datalogi; in Swedish: datavetenskap, “data science”).
Besides the traditionally close relationship between science and mathematics, there is a concrete reason that science and mathematics unite in computer science around the study of algorithms. Scientific computing applications often consist of small pieces of code that execute millions of times.5 This means that any change to the central piece of code that makes it more efficient can result in saving time, and thereby reducing costs. In turn, this has led to a focus on efficient algorithms – an area where mathematics has had early and large successes in the field of computing.
Neil Jones, professor of programming languages, provides a good example of a view of computer science that combines mathematics, algorithms, and formal systems. He regards a programming language, L , as a mathematical function that maps programs to their meanings:6
[ ]L : Programs -> Meanings
An individual program, p , is similarly regarded as a mathematical function from input to output data:
[p]L : Input -> Output
This view of programs and programming languages leads, unsurprisingly, to a research focus on the mathematical functions that can be expressed by a computer.7
1 Kernighan & Ritchie 1978 [1988] p. 1.
2 Lammers 1986 p. 15.
3 Stroustrup 1985 [1997] p. 23.
4 Naur 1995 p. 9.
5 Patterson & Hennessy 1997 p. 86.
6 Filinski et al. 2005 chp. 1, p. 7.
7 Techniques to study programs as mathematical constructs have been developed within the field of formal semantics, though “it is fairly involved to show even trivial programs are correct.” Winskel 1993 p. 95.
3.3.3 Abstraction
A common theme in computer science thinking is abstraction; both as an ideal and as an explanation of progress. The standard explanation for the evolution of the high-level programming languages of our day runs as follows:1 In the beginning programs were written directly in binary machine code. From this evolved the slightly more abstract assembly code, in which programmers do not have to remember the numbers of locations in the machine’s memory but can use names instead. After that came low-level programming languages which are even more convenient for the programmer to use and regarded as more abstract. Finally, there are the high-level programming languages, which are seen as the most abstract and which a programmer can use without knowing many of the technical details of the machines he is programming for. Thus, historically, what are today known as low-level programming languages were once thought of as high-level.
Abstraction in this sense means that the programming language does not closely describe what the machine does, but instead presents a symbolic notation – an abstraction – that is easier to use. Abstract programming languages are considered to lead to a more natural way of thinking as well as being more productive, because the programmer has to write fewer lines of code.2 Conversely, assembly language and low-level programming languages are considered to lead to an unnatural style of programming: “Assembly … [is] forcing the programmer to think like the machine.” 3 This notion is a variant of an underlying idea common to much of computer science: that a programming language in some sense sets the limits for what the programmer can think, and that abstraction is the ideal for thinking. According to Stroustrup, a programming language is a vehicle for machine actions, plus concepts to use when thinking.4 Moreover, it is a common viewpoint that “every high-level language provides abstraction of machine services.” 5 Combined with Stroustrup’s definition, this implies that a good, high-level programming language provides abstract concepts to think about machine actions that are themselves presented as abstractions.6 Jones writes that high-level programming languages abstract away from any particular machine; this viewpoint of course works well with an orientation of research away from engineering and towards mathematics.7
The ideal of abstraction is not only applied to program code but also to the textbooks and articles that explain programming languages. To give an example, here is a textbook definition of what a type system is:
“A type system is a tractable syntactic method for proving the absence of certain program behaviours by classifying phrases according to the kinds of values they produce.” 8
The definition is so abstract and general that it hardly enlightens anyone who does not already know what a type system is. A definition in plain language could be: a type system is a mechanism in a programming language that makes sure that different kinds of values do not accidently get mixed up; for example numbers and letters, or integers and fractional numbers.
According to the same textbook, the history of type systems begins in the 1870s with Gottlob Frege’s works on formal logic.9 However, Frege did not have programming languages in mind: type systems were first introduced to programming languages in the 1950s for reasons of efficiency.10 To place the beginnings of type systems with Frege has the effect of maximising the emphasis on formal, logical, and mathematical aspects at the cost of downplaying practical aspects.
Finally, we should note with caution that abstraction is sometimes given an unrealistic importance, as if “more abstract” is the same as “better”. In reality, to regard a program or programming language as abstract is simply a perspective. Any given program must run as concrete instructions on a concrete computer in order to be useful, no matter how “abstract” the programming language is. From the perspective of the machine that executes the program, the high-level programming language program is every bit as concrete as binary machine code – the layers of programs that make up a high-level programming language are perhaps thought of as abstractions, but they exist in a concrete form.
1 Patterson & Hennessy 1997 pp. 6–8.
2 Ibid.
3 Ibid. p. 6.
4 Stroustrup 1985 [1997] p. 9.
5 Pierce 2002 p. 6.
6 The general view described here is not exactly Stroustrup’s own position. He advocates that the programming language, sans the concepts for thinking, should be “close to the machine” i.e. non-abstract. Stroustrup 1985 [1997] p. 9.
7 Filinski et al. 2005 chp. 1, p. 3.
8 Pierce 2002 p. 1.
9 Ibid. p. 11.
10 Ibid. p. 8 f.
3.3.4 Machine-orientation
Despite, or perhaps because of, the emphasis placed on mathematics and logic in computer science, the thinking is remarkably oriented towards the machines, meaning that the world is seen almost exclusively in terms of what the computers can do, rather than what people do. We read in a quote above that “Reasoning about situations means constructing arguments about them; we want to do this formally, so that the arguments are valid and can be defended rigorously, or executed on a machine.” 1 This quote can also be read as indicating that computer scientists should work with formal systems precisely because they can be executed by a machine. Thus, the notion of an abstract machine comes to dictate the focus of computer science.
Within computer science, the study of programming languages is generally divided into syntax and semantics, where syntax is the study of programming notation and semantics the study of the meaning of programs. This notion of meaning, however, includes only the mathematical formalization of a program, which is also what can be executed on a machine.2 The usual sense of semantics – which is the meaning a program has to a human – is lost.
Paulson writes that an engineer understands a bicycle in terms of its components, and therefore a programmer should also understand a program in terms of components.3 This thinking is a kind of reification: mistaking concepts for concrete things.4 Machine-oriented thinking easily leads to this kind of philosophical mistake, because focusing solely on the machine means that the inherent ambiguity of human thinking is ignored.
1 Huth & Ryan 2000 [2004] p. 1.
2 Filinski et al. 2005 chp. 1, p. 2.
3 Paulson 1991 [1996] p. 59.
4 Latour observes that reification happens frequently in science and has explained it as a consequence of the rush to develop unassailable theories and establish facts. Latour 1987 p. 91 f.
3.3.5 Mathematics as premise
There is within computer science an unfortunate tendency to ignore the premises of the mathematical systems upon which the research focuses. Naur calls it a pattern in ignoring subjectivity in computer science.1 By “subjectivity”, Naur largely means the consequences for the people who are to use the programs, that is, the usefulness of the programs. According to Naur, computer science publications commonly postulate the need for a new notation, which is then presented in thorough technical details. The conclusion then claims that the need is now met, without any evidence to support this claim.
Take, for example, the doctoral dissertation of Ulla Solin Animation of Parallel Algorithms from 1992. This is not badly-executed research – on the contrary, it is exemplary in fulfilling the expectations of a dissertation in computer science and precisely because of that it serves well as an example. In the introduction to the dissertation, Solin briefly explains what the subject is: making animations out of programs.2 She then proceeds in seven chapters to demonstrate a detailed method of constructing animated programs, complete with mathematical proof. The dissertation’s conclusion begins with the statement: “It is obvious that animation has a wide range of potential use and should become an important tool for testing and analysing algorithms.” 3 However, it is not at all possible to conclude this from the dissertation, which concerns only the details of a solution to the problem that has been posed. The statement that animation should be an important tool is actually the direct opposite of a conclusion: it is the premise for the whole dissertation. Without assuming animation of programs to be important, it makes little sense to devote a dissertation to it. Nor is it obvious that animation is as useful as claimed – history so far has shown that animating programs is not actually an important tool for programming.4
An example on a larger scale comes from Jones, who conducted research in automatic compiler generation since 1980.5 Twenty-five years later he writes that: “It is characteristic of our grand dream [of automatic compiler generation] that we are just now beginning to understand which problems really need to be solved.” 6 However, Jones does not call for an examination of the premises of the dream, but rather advocates more mathematics: “What is needed is rather a better fundamental understanding of the theory and practice of binding time transformations … ”.7
1 Naur 1995 p. 10.
2 That is, making a computer-generated animated film clip out of a computer program to illustrate how that program is behaving.
3 Solin 1992 p. 101.
4 It is not for want of trying. So-called visual programming is a long-standing idea held by computer scientists. See for example the August 1985 issue of IEEE Computer magazine devoted to “Visual Programming”, including an article on “Animating Programs Using Smalltalk”.
5 Jones & Schmidt 1980: “Compiler Generation from Denotational Semantics.”
6 Filinski et al. 2005 chp. 1, p. 22.
7 Ibid.
3.3.6 Work processes
We will now look at what computer science has to say about programming as an activity – that is, about the work processes of programming. According to Dijkstra, programming is essentially a matter of effective thinking.1 Dijkstra sees the programming field as being in an ongoing transition from a craft to a science. The goal of using computers, and of thinking, is to reduce the amount of reasoning that is necessary in order to arrive at effective, intellectually elegant solutions to problems. What Dijkstra means by “reasoning” is essentially calculation, since it is something a computer can do.2 It is not difficult to discern the ideals of a mathematician in Dijkstra’s approach to programming.
For Simonyi, the central task in programming is imagining and writing code to maintain invariances in data structures. “Maintaining invariances” is a concept that comes from mathematical analysis of data structures. Simonyi writes that: “Writing the code to maintain invariances is a relatively simple progression of craftsmanship, but it requires a lot of care and discipline.” 3
Stroustrup has a simple phase model of development that is reminiscent of software engineering’s waterfall model. According to Stroustrup, the development process consists first of analysis, then design, and finally programming.4 There is a marked difference from software engineering, however, in that Stroustrup emphasizes that many of the details of the problem only become understood through programming. This aspect of the model seems more in line with Agile thinking, which discourages programmers from planning too far ahead according to the view that only working code can show if the program solves the right problem.
Since, as we have seen, computer science is preoccupied with mathematics and a machine-oriented perspective, it has little to say regarding the programming work process compared to software engineering and Agile thinking. In general, according to computer science the way a programmer works is much the same as the way a stereotypical mathematician works. One notion is that he works on the basis of genius inspiration, which is basically inexplicable; another notion is that he follows a very personal and ad hoc process that cannot meaningfully be systematized.
The famous computer scientist Donald E. Knuth can serve as an illustrative example of the “genius” perception of programming processes in computer science. Knuth is the author of the colossal, unfinished, and highly acclaimed The Art of Computer Programming. His article “The Errors of TEX” tells the story of one man – the genius of the story – who worked alone for 10 years on a typesetting program that later went on to become a huge success.5 Regarding the programming process, Knuth writes:
“My feeling is that when we prepare a program, the experience can be just like composing poetry or music … programming can give us both intellectual and emotional satisfaction, because it is a real achievement to master complexity and to establish a system of consistent rules.
Furthermore, when we read other people’s programs, we can recognize some of them as genuine works of art.” 6
Naur writes that programming is primarily a question of achieving a certain kind of insight.7 He calls this “building a theory of the matters at hand”. Programming is therefore a process of gaining insight, and it is accordingly not possible to find any single correct method for programming in general since every situation demands a unique insight. What Naur calls “theory” is in my opinion close to what is, in hermeneutical theory, termed “understanding”; and as we shall see in Chapter 4 (Game programming), Naur’s view of the programming process appears to be quite close to a hermeneutical understanding of programming.
2 Dijkstra 1975 p. 6 f.
3 Lammers 1986 p. 15.
4 Stroustrup 1985 [1997] p. 15.
6 Knuth 1992 p. 7 f.
7 Naur 1985 [2001] p. 186.